
“Is depression related to cannabis?”: A knowledge-infused model for entity and relation extraction with limited Supervision
Published in AAAI 2021 Spring Symposium on Combining Machine Learning and Knowledge Engineering (AAAI-MAKE), 2021
This paper studies how to extract structured cannabis-depression relationships from noisy Twitter text when only a small expert-labeled subset is available.
Why it matters
- Cannabis is frequently discussed as a potential mental health aid, but scientific evidence linking cannabis and depression remains inconclusive.
- Twitter contains large volumes of self-reported experiences, yet extracting structured relationships from informal text is technically difficult.
- Standard deep learning models require large annotated datasets, which are costly when domain experts are involved.
- In this study, only 3,000 of 11,000 tweets were expert-labeled (Cohen's kappa = 0.8), creating a limited supervision setting.
What we did
- We propose a knowledge-infused relation extraction model that combines Drug Abuse Ontology (315 entities, 31 relations), DSM-5 and related clinical lexicons, GPT-3 embeddings, and supervised contrastive learning with triplet loss.
- We extract and classify three relationships between cannabis and depression: Reason, Effect, and Addiction.
- The model reaches an F1 score of 75.37, reported as a +11.28 point gain over the strongest baseline.
- Ablation results show removing contrastive learning reduces F1 by 6.46 points, and removing knowledge infusion reduces F1 by 9.01 points.
- The learned representation space is then used to label the remaining ~7,000 tweets.
| Method | Precision | Recall | F1-Score |
|---|---|---|---|
| BERT | 64.49 | 63.22 | 63.85 |
| BioBERT | 63.97 | 62.15 | 63.06 |
| BERTPE | 60.64 | 56.51 | 58.50 |
| BERTPE+PA | 65.41 | 65.25 | 64.50 |
| Proposed Model | 74.60 | 76.17 | 75.37 |
As shown in Table I, the knowledge-infused contrastive approach outperforms all baselines.
How it works
- Knowledge-guided phrase extraction: Map tweet n-grams to cannabis and depression entities using ontology matching (cosine similarity >= 0.75).
- Contextual embeddings: Use GPT-3 to obtain phrase representations.
- Supervised contrastive learning: Train anchor-positive-negative triplets to separate relation classes in embedding space.
- Weak supervision extension: Label the remaining ~7,000 tweets using the learned metric and clustering.
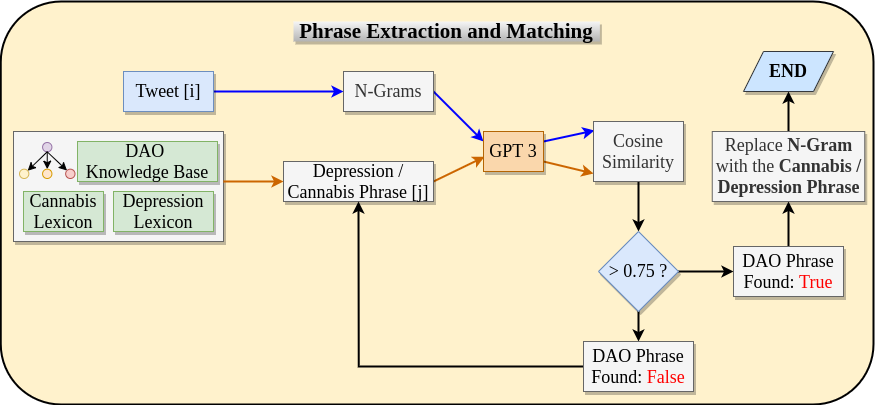
The extraction pipeline (Figure 1) shows how ontology-matched phrases are embedded before relation classification.
Key contributions
- A knowledge-infused neural model for cannabis-depression relation extraction.
- Integration of GPT-3 embeddings with supervised contrastive learning under limited supervision.
- An absolute +11.28 F1 improvement over the strongest BERT-based baseline.
- Release of an annotated dataset covering 3,000 expert-labeled tweets and model-labeled data for the full 11,000 tweet set.
Recommended citation: Kaushik Roy, Usha Lokala, Vedant Khandelwal, and Amit Sheth. (2021). "Is depression related to cannabis?: A knowledge-infused model for entity and relation extraction with limited Supervision." Proceedings of the AAAI 2021 Spring Symposium on Combining Machine Learning and Knowledge Engineering (AAAI-MAKE 2021).
Download Paper