
Inductive Logic Programming for Heuristic Search
Published in Accepted at both IJCLR 2025 (5th International Joint Conference on Learning & Reasoning) and the ICAPS 2025 Workshop on Planning and Reinforcement Learning (PRL), 2025
This paper learns cost-to-go heuristic functions as logic programs, combining interpretable symbolic structure with effective A* search performance.
Why it matters
- Heuristic search depends on accurate cost-to-go functions to efficiently solve pathfinding problems.
- Deep neural network heuristics are not explainable, making knowledge extraction difficult.
- It has not been shown how to learn heuristic functions represented as logic programs.
- Explainable heuristics could enable structured knowledge discovery from domains such as puzzles, robotics, or chemistry.
- Learning heuristics directly as logic programs may combine interpretability with search effectiveness.
What we did
- Propose an algorithm to learn cost-to-go heuristic functions as logic programs using dynamic programming and ILP.
- Use A* search (multi-step lookahead) to compute updated heuristic values instead of one-step Bellman updates.
- Represent the heuristic as a dictionary mapping cost-to-go values to learned logic programs.
- Introduce predicate reuse, where rules learned for smaller depths are reused to learn deeper cost-to-go rules.
- Evaluate on the 8-puzzle (181,440 solvable states), showing improved accuracy with larger samples (for example, median R² up to 0.6925 with 2,000 states) and up to 100% optimal solutions when used with A* (Table I).
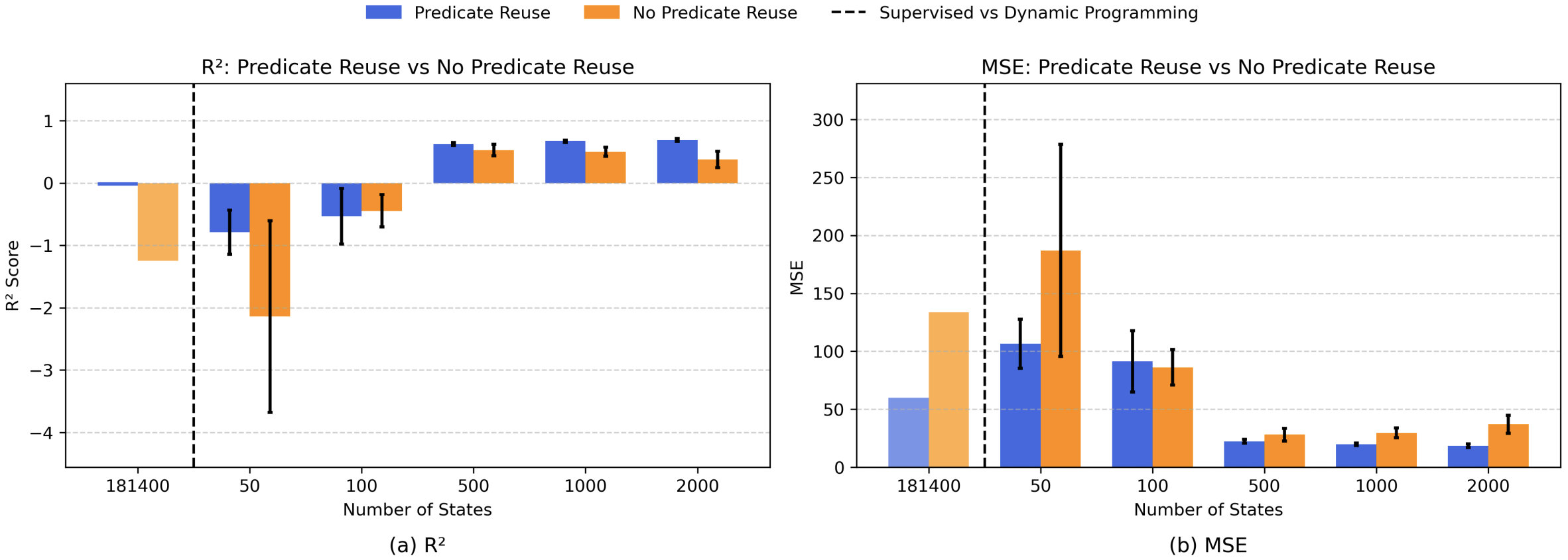
As shown in Figure 1, increasing the number of sampled states improves R² and reduces MSE, with predicate reuse yielding more accurate heuristics in most settings.
How it works
- Represent the heuristic as a dictionary mapping cost-to-go values to logic programs.
- Use A* to compute updated path costs for sampled states (multi-step lookahead).
- Convert updated values into positive and negative ILP examples for a target cost-to-go.
- Learn a logic program for each depth using Popper.
- Reuse previously learned clauses as background knowledge to build higher-cost rules.
Key contributions
- Introduce an algorithm to learn heuristic functions as logic programs via dynamic programming and ILP.
- Propose predicate reuse to incrementally construct deeper cost-to-go rules.
- Show that increasing sample size improves heuristic accuracy (for example, median R² up to 0.6925 with 2,000 states).
- Demonstrate that learned heuristics achieve up to 100% optimal solutions under A* search (Table I).
| States (hour/s) | Predicate Reuse | Len | Nodes | Secs | Nodes/Sec | Solved (%) | Optimal (%) |
|---|---|---|---|---|---|---|---|
| 181440 (1 hour) | Yes | 17.27 | 118.33 | 155.58 | 1.02 | 90.0 | 100.0 |
| 181440 (0.5 hours) | No | 17.73 | 1357.49 | 117.61 | 11.65 | 98.0 | 100.0 |
| 181440 (1 hour) | No | 17.73 | 1332.29 | 132.59 | 10.21 | 98.0 | 100.0 |
| 181440 (2 hours) | No | 17.73 | 560.18 | 97.54 | 6.00 | 98.0 | 100.0 |
| 181440 (4 hours) | No | 17.73 | 499.61 | 111.39 | 4.53 | 98.0 | 100.0 |
| 181440 (8 hours) | No | 17.73 | 347.76 | 91.18 | 3.89 | 98.0 | 100.0 |
| 181440 (120 hours) | No | 17.92 | 112.28 | 90.43 | 1.33 | 100.0 | 100.0 |
Table I shows that the learned heuristic achieves up to 100% optimal solutions (learned for 181,440 states).
Recommended citation: Rojina Panta*, Vedant Khandelwal*, Celeste Veronese, Amit Sheth, Daniele Meli, and Forest Agostinelli. (2025). "Inductive Logic Programming for Heuristic Search." Accepted at both IJCLR 2025 (5th International Joint Conference on Learning & Reasoning) and the ICAPS 2025 Workshop on Planning and Reinforcement Learning (PRL). (* Equal contribution)
Download Paper | Download Slides