
Language Models Coupled with Metacognition Can Outperform Reasoning Models
Published in arXiv preprint arXiv:2508.17959 (under review at ICML 2026), 2025
This paper studies whether a training-free metacognitive control loop can make a fast language model reliable enough to reduce or outperform default use of slower reasoning models.
Why it matters
- LLMs are fast, but they often fail on tasks requiring strict global constraints (such as valid graph colorings) or precise localized edits (such as program repair).
- LRMs can be more deliberate, but they are typically slower and more compute-heavy, making default use expensive.
- This paper asks whether a training-free metacognitive loop can make an LLM reliable enough to reduce (or outperform) LRM usage.
What we did
- We introduce SOFAI-LM, a generalized SOFAI architecture that coordinates a fast S1 (LLM) with a slower S2 (LRM) using metacognitive governance.
- The controller evaluates each S1 attempt, generates targeted feedback (plus small examples), and retries for T iterations before selective fallback to S2.
- Evaluation spans graph coloring (including size 25) and code debugging (DebugBench).
- On graph coloring (size 25), SOFAI-LM reaches 42% success with lower average time than the standalone LRM.
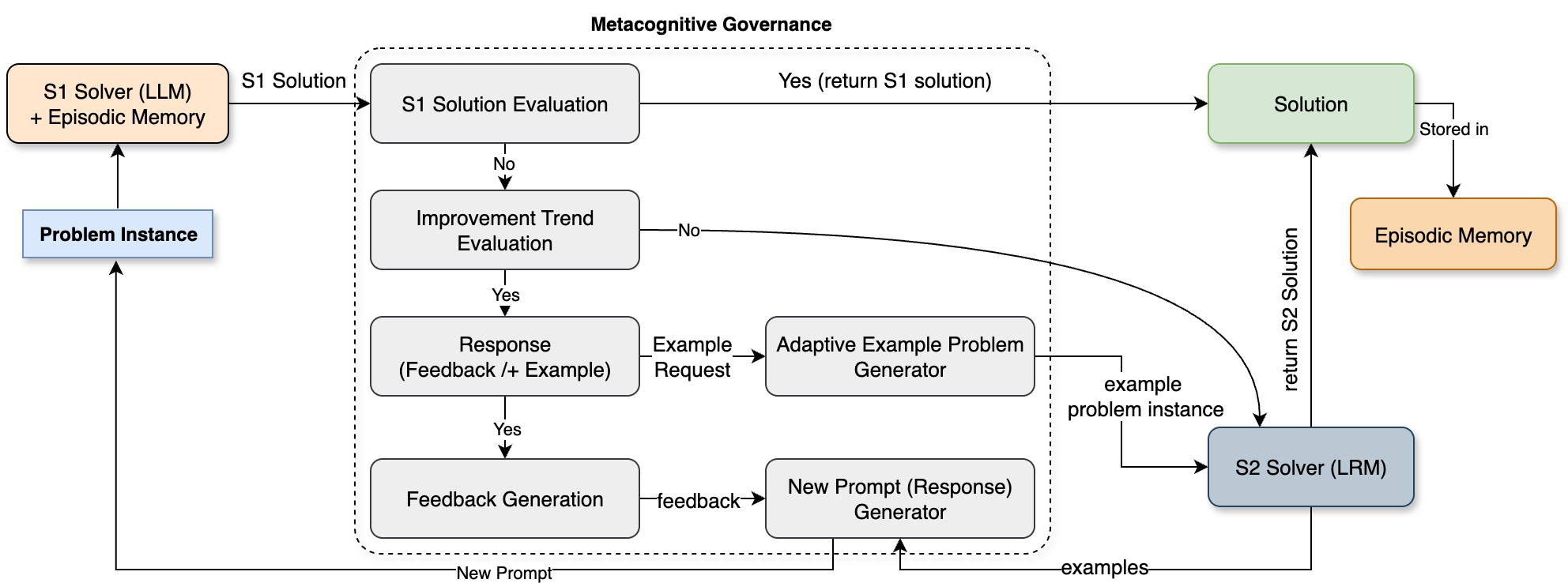
Figure 1 shows how the controller iterates with S1 before deciding whether to call S2.
How it works
- S1 attempt: the LLM outputs a candidate solution in a strict format.
- Check: the metacognition module verifies correctness (for example, conflict violations or test outcomes).
- Feedback: generates Single-Line versus Multi-Line feedback and can include a small corrective example.
- Memory: stores minimal or extended episodic traces for the next iteration.
- Fallback: if S1 does not converge within T, invoke S2 with Problem-Only (PO), Best Attempt (BA), or Full History (FH).

Figure 2 makes the feedback mechanism tangible with a real failure case and its corrective hint.
Key contributions
- A training-free metacognitive feedback loop that iteratively improves an LLM without fine-tuning.
- A domain-grounded study showing feedback-driven LLM iterations can match or exceed a standalone LRM on graph coloring and debugging.
- An ablation of feedback format and episodic memory (MLF vs SLF; MEM vs EEM) and their effect on success and time.
- An analysis of what to pass to S2 (PO/BA/FH) and when it helps across global-constraint versus local-fix domains.
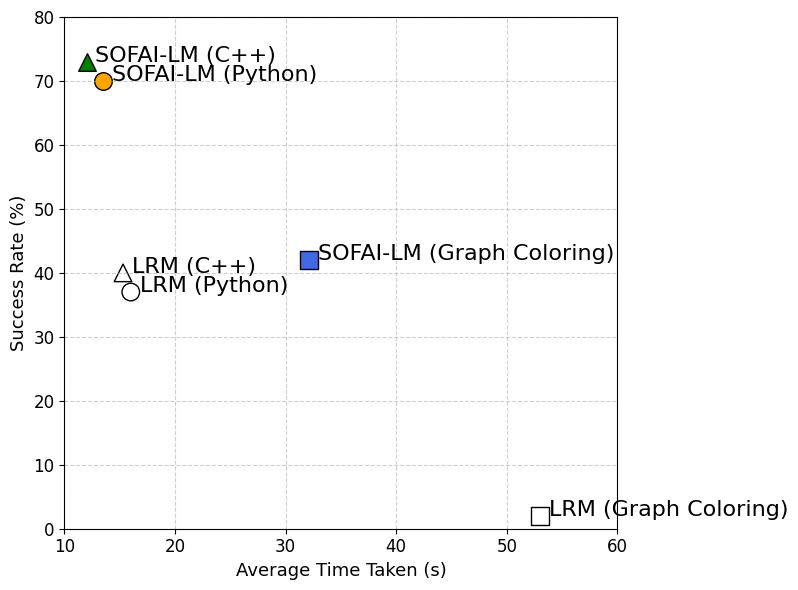
Figure 3 summarizes the main efficiency-accuracy trade-off the paper measures.
Recommended citation: Vedant Khandelwal, Francesca Rossi, Keerthiram Murugesan, Erik Miehling, Murray Campbell, Karthikeyan Natesan Ramamurthy, and Lior Horesh. (2025). "Language Models Coupled with Metacognition Can Outperform Reasoning Models." arXiv preprint arXiv:2508.17959 (under review at ICML 2026).
Download Paper