
Toward Neurosymbolic Reinforcement Learning via Editable Specifications
Published in AAAI-MAKE 2026, 2026
This paper proposes a practical path for adapting reinforcement learning systems through editable symbolic requirements rather than retraining.
Why it matters
- Reinforcement learning systems are typically adapted through retraining, even when deployment changes are structured requirement updates like revised safety rules or updated operational constraints.
- This adaptation primitive is expensive, hard to audit, and can entangle unintended behavioral shifts with intended changes.
- In real deployments, many updates are local and human-legible edits, such as forbidding an action under a mode switch or changing energy-speed tradeoffs.
- Those edits should produce immediate and inspectable behavioral effects without requiring gradient updates.
What we did
We treat an editable specification as a first-class interface for adaptation. The specification is represented as:
G = (R, C, P)Rdefines action applicability rules.Cdefines hard constraints (forbidden behavior).Pdefines soft preferences (tradeoffs).
The policy is conditioned on G at execution time, while enforcement and preference shaping are applied directly in the decision loop.
A_G(s) = {a in A | C(s, a, G) = 0}r_G(s, a) = r(s, a) - lambda * c_P(s, a, G)Requirement updates are modeled as edits G' = Delta(G), enabling immediate behavioral changes for in-schema edits with zero gradient updates.
How it works
- Maintain a persistent knowledge graph
G = (R, C, P)with local edit operations and provenance tracking. - Condition the policy
pi_theta(a | s, G)on the specification (optionally via graph embedding). - Enforce hard constraints via runtime shielding (action masking or safe-set projection).
- Apply soft preferences through reward shaping or action reweighting.
- When requirements change, apply an edit
Deltato produceG'; the next decision step recomputes feasibility and preferences without modifying policy parameters.
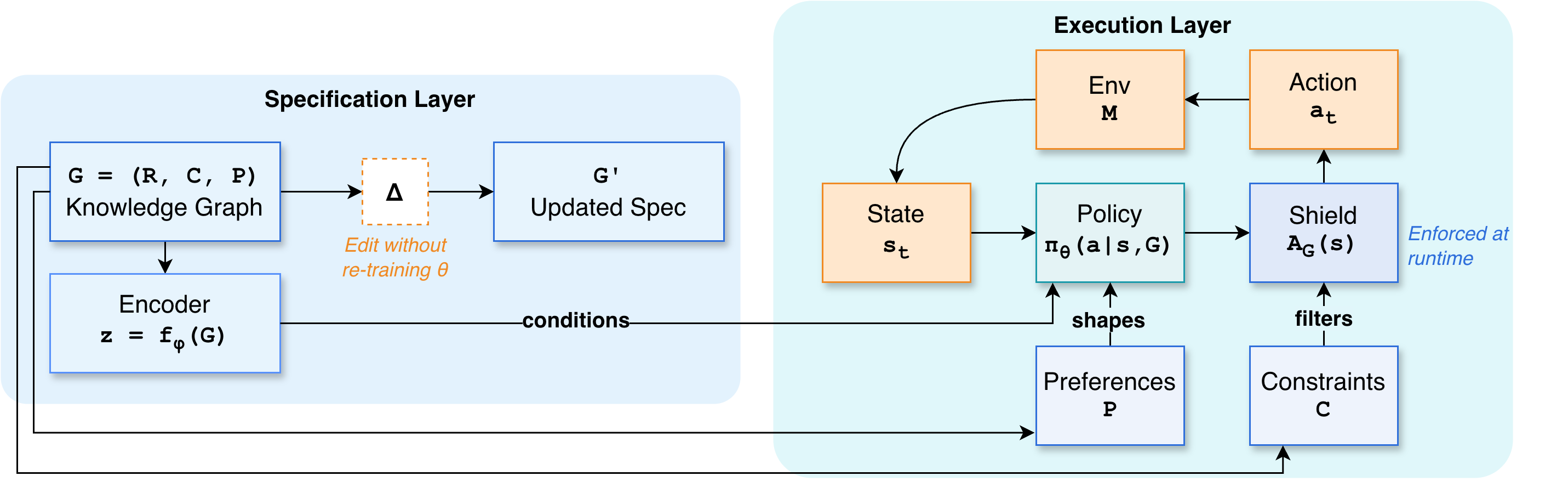
Figure 1 illustrates how specification edits flow directly into constraint enforcement and preference shaping in the execution loop.
Key contributions
- Introduces editable knowledge-graph specifications as an operational interface for RL adaptation.
- Formalizes execution-time semantics where constraint edits deterministically change the feasible action set.
- Separates competence (learned policy) from compliance (runtime shielding and preference shaping).
- Defines an edit-based generalization objective, evaluating post-edit success without retraining.
- Positions auditability and requirement traceability as core properties of neurosymbolic RL systems.
Recommended citation: Vedant Khandelwal, Hong Yung Yip, and Amit Sheth (2026). "Toward Neurosymbolic Reinforcement Learning via Editable Specifications." AAAI-MAKE 2026.
Download Paper