
A Domain-Agnostic Neurosymbolic Approach for Big Social Data Analysis: Evaluating Mental Health Sentiment on Social Media during COVID-19
Published in IEEE International Conference on Big Data, 2024
This paper presents a domain-agnostic neurosymbolic framework for analyzing large-scale social media signals and monitoring depression, addiction, and anxiety during COVID-19.
Why it matters
- Social media generates large-scale, rapidly evolving signals (about 12 billion tweets during COVID-19) that can inform mental health surveillance.
- Purely data-driven models struggle with emerging terms, including pandemic-specific slang, which limits near-real-time monitoring quality.
- Large language model baselines can require high computational cost (more than 6 to 8 hours to converge in reported experiments), reducing practical rapid adaptation.
- Public-health deployment needs both high accuracy and adaptability across depression, anxiety, and addiction signals.
What we did
- Proposed a domain-agnostic neurosymbolic framework that integrates Word2Vec with multiple knowledge bases, including DSM-5, DAO, UMLS, and DBpedia.
- Introduced SEDO to modulate tweet embeddings through a learned weight matrix formulated via a Sylvester equation.
- Trained classifiers on semantically filtered data (900M to 600M tweets) and evaluated binary tasks for depression, addiction, and anxiety.
- Achieved F1 scores above 92%, outperforming zero-shot LLM baselines (about 70% to 80% F1) while converging in 40 to 55 minutes.
- Validated robustness with triangulation and ablation studies, including a +5.03% F1 gain for depression after SEDO fine-tuning.
How it works
- Semantic Gap Management (B1): Train domain-specific LDA and Word2Vec models; dynamically update lexicons with knowledge bases and neologisms.
- Metadata Scoring (B2): Compute semantic mapping and proximity scores; normalize index scores as supervision signals.
- SEDO-based Infusion: Solve a Sylvester equation to learn a weight matrix that aligns tweet and knowledge-base embedding spaces.
- Adaptive Classification (B3): Train binary classifiers (for example, Balanced Random Forest) for depression, addiction, and anxiety.
- Validation: Perform triangulation and ablation studies to measure robustness and component-level gains.
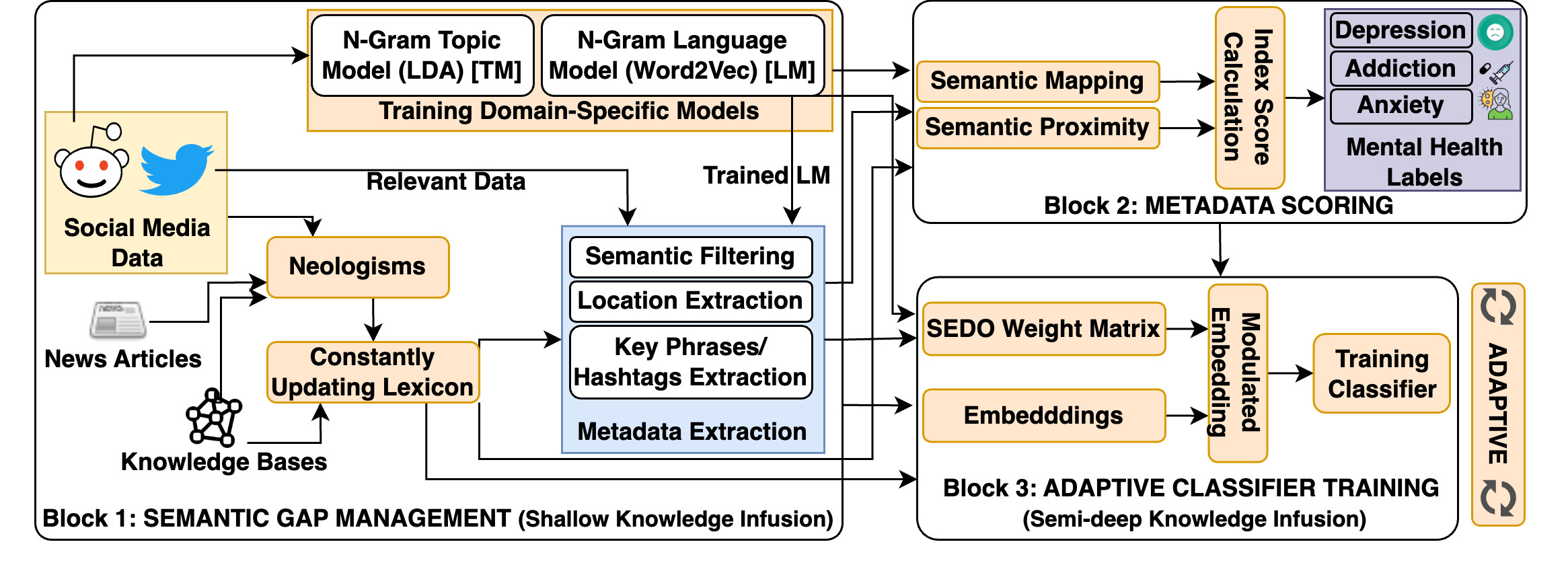
The architecture (Figure 1) shows how knowledge infusion and embedding modulation interact across three stages.
Key contributions
- A multi-stage neurosymbolic architecture that combines shallow and semi-deep knowledge infusion for dynamic social media analysis.
- Empirical results above 92% F1, with consistent gains over zero-shot LLM baselines (about 89% to 93.6% versus 70% to 80%).
- Demonstrated efficiency: 40 to 55 minute convergence versus more than 6 to 8 hours for LLM baselines under similar settings.
- Triangulation and ablation studies showing measurable SEDO and knowledge-integration effects (for example, +5.03% F1 for depression after fine-tuning).
| Category | Model | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Depression | LLama | 74.23 | 70.57 | 72.34 |
| Depression | Phi | 71.67 | 66.42 | 68.95 |
| Depression | Mistral | 76.51 | 71.38 | 73.87 |
| Depression | Neurosymbolic | 90.45 | 87.29 | 88.84 |
| Addiction | LLama | 77.24 | 73.68 | 75.42 |
| Addiction | Phi | 73.32 | 69.75 | 71.49 |
| Addiction | Mistral | 78.45 | 74.67 | 76.51 |
| Addiction | Neurosymbolic | 92.18 | 88.36 | 90.22 |
| Anxiety | LLama | 78.56 | 74.82 | 76.66 |
| Anxiety | Phi | 74.38 | 70.61 | 72.43 |
| Anxiety | Mistral | 80.33 | 76.89 | 78.56 |
| Anxiety | Neurosymbolic | 93.25 | 90.52 | 91.85 |
As shown in Table I, the neurosymbolic approach consistently exceeds LLM performance in F1 score.
| Category | Model | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Depression | NB | 84.85 (-24%) | 82.68 (-25%) | 83.75 (-27%) |
| Depression | RF | 91.98 (-28%) | 91.81 (-26%) | 91.89 (-23%) |
| Depression | BRF | 92.32 (-27%) | 92.43 (-24%) | 92.37 (-29%) |
| Depression | BSRF | 94.12 (-29%) | 93.02 (-22%) | 93.57 (-28%) |
| Addiction | NB | 82.74 (-26%) | 80.46 (-21%) | 81.58 (-25%) |
| Addiction | RF | 90.02 (-22%) | 90.36 (-20%) | 90.19 (-23%) |
| Addiction | BRF | 91.53 (-28%) | 91.78 (-26%) | 91.65 (-29%) |
| Addiction | BSRF | 91.64 (-27%) | 91.82 (-24%) | 91.73 (-28%) |
| Anxiety | NB | 82.53 (-25%) | 81.87 (-24%) | 82.20 (-22%) |
| Anxiety | RF | 90.76 (-23%) | 92.78 (-28%) | 91.76 (-21%) |
| Anxiety | BRF | 94.37 (-27%) | 93.87 (-25%) | 94.12 (-29%) |
| Anxiety | BSRF | 93.46 (-24%) | 93.85 (-27%) | 93.65 (-28%) |
Table II quantifies the degradation when SEDO is removed, underscoring its impact.
Recommended citation: Vedant Khandelwal, Manas Gaur, Ugur Kursuncu, Valerie Shalin, and Amit Sheth. (2024). "A Domain-Agnostic Neurosymbolic Approach for Big Social Data Analysis: Evaluating Mental Health Sentiment on Social Media during COVID-19." Proceedings of the IEEE International Conference on Big Data.
Download Paper | Download Slides